用Python扫描图书条形码并构建个人藏书清单
自己攒了几箱子的书,想着给它们建个数据库,试了知乎上提到的几款软件,要么是软件已经凉了,要么是需要收费。最可恨的是,我用某小程序顺利扫描了七十余本书,最后到处的表格里却出现了一句“说明:未付费书馆仅支持导出10条数据,付费书馆导出数据无限制。”当然了,收费无可厚非,你能不能提前说一声啊!于是我一气之下决定自己写一个Python程序,扫描图书的条形码(ISBN),通过公开的API获取相关信息,并保存图书信息到本地Excel表格中,同时也获取图书封面到本地,构建自己的个人藏书清单。
先看看最终效果。
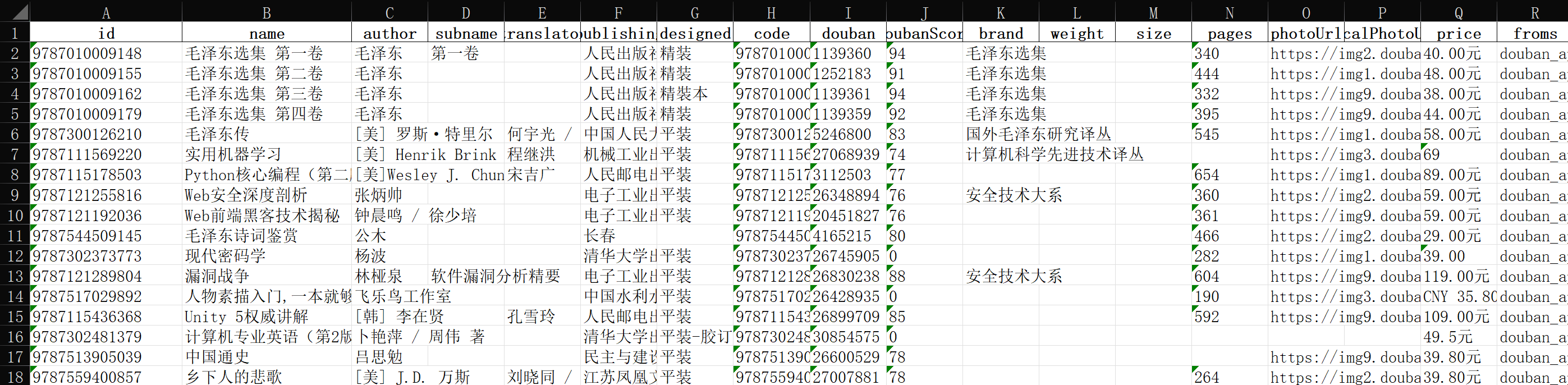
清单:
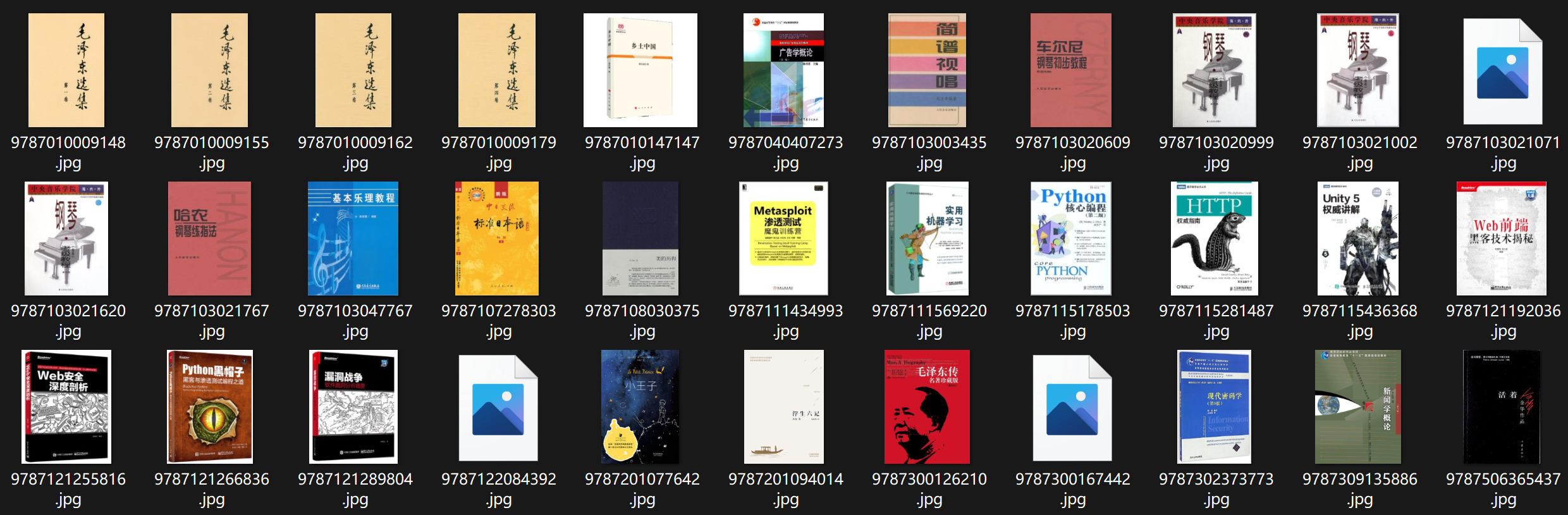
封面:
思路
- 用python OpenCV调用摄像头;
- 使用
zbar库扫描ISBN条形码; - 调用查询接口获取图书信息;
- 将图书信息保存;
调用摄像头
安装python的OpenCV库
opencv-python1
pip3 install opencv-python
如果没有安装
numpy则会自动安装上去;主要代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import cv2
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit(0)
while True:
ret, frame = cap.read()
if not ret:
print("Failed to capture image")
continue
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
扫描条形码
安装python的
zbar库pyzbar1
pip3 install pyzbar
解决错误
Unable to find zbar shared library(Ubuntu)1
sudo apt-get install libzbar-dev
扫描条形码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import cv2
from pyzbar.pyzbar import decode
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit(0)
while True:
ret, frame = cap.read()
if not ret:
print("Failed to capture image")
continue
cv2.imshow('frame', frame)
barcodes = decode(frame)
for barcode in barcodes:
print("barcode = ", barcode.data)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
检索ISBN数据
首先找到一个公开的ISBN接口,这里我用的是中文ISBN公开信息查询接口 | 极客分享 (jike.xyz),用法如下(需要申请
apikey,鼓励大家给API提供者捐赠项目维持经费):1
2
3
4
5
6
7
8
9
10
11
12
13import requests
url = "https://api.jike.xyz/situ/book/isbn/"
isbn = "9787020024759"
apikey = "替换为申请的apikey"
full_url = url + isbn + "?apikey=" + apikey
response = requests.request("GET", full_url)
print(response.text)安装依赖
1
pip3 install requests
整合思路
- 扫描到一个ISBN后暂停捕获画面;
- 通过API获取该ISBN对应的书籍数据;
- 处理该数据(保存或不保存);
- 继续扫描;
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39from time import sleep
import cv2
from pyzbar.pyzbar import decode
import requests
url = "https://api.jike.xyz/situ/book/isbn/"
isbn = "9787020024759"
apikey = "替换为申请的apikey"
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit(0)
while True:
ret, frame = cap.read()
if not ret:
print("Failed to capture image")
continue
cv2.imshow('frame', frame)
barcodes = decode(frame)
for barcode in barcodes:
isbn = barcode.data.decode("utf-8")
full_url = url + isbn + "?apikey=" + apikey
response = requests.request("GET", full_url)
print(response.text)
sleep(3)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
图书信息数据的解析与保存
返回的数据为
json格式,需要解析出具体的字段,提供API的网站给出了返回参数的说明,其实远远不止这些,可以print出来看一下:名称 类型 说明 subnamestring书名 authorstring作者 authorIntrostring作者简介 photoUrlstring图片封面 publishingstring出版社 publishedstring出版时间 descriptionstring图书简介 doubanScorestring豆瓣评分 这里使用
json.loads()函数来解析:1
2
3
4
5
6
7
8
9
10
11
12json_data = json.loads(response.text)
ret = json_data["ret"]
msg = json_data["msg"]
data = json_data["data"]
print("返回信息: " + msg + "(ISBN" + isbn + ")")
if ret == 0 and data != None:
is_save = input("是否保存?(y/n)")
if is_save == 'y' or is_save == 'Y':
save_book(data)
else:
print("未找到该书籍")
sleep(1)可以将数据保存到excel,可以使用pandas库来实现,操作比较方便,首先安装依赖:
1
pip3 install openpyxl, pandas
具体保存的思路就是,如果没有文件先创建文件,设置列首,如果已经有了那就追加数据,方法是先把数据读出来,然后再追加,然后写回去:
1
2
3
4
5
6
7
8
9
10
11
12def save_book(data):
file_path = os.path.join(os.path.dirname(__file__), 'books.xlsx')
if not os.path.exists(file_path):
df = pd.DataFrame(columns=['id', 'name', 'author', 'subname', 'translator', 'publishing', 'designed',
'code', 'douban', 'doubanScore', 'brand', 'weight', 'size', 'pages', 'photoUrl', 'localPhotoUrl',
'price', 'froms', 'num', 'createTime', 'uptime', 'authorIntro', 'description', 'reviews', 'tags'], dtype=str)
df.to_excel(file_path, index=False)
df = pd.read_excel(file_path, dtype=str)
for key in data.keys():
data[key] = str(data[key])
df = df.append(data, ignore_index=True)
df.to_excel(file_path, index=False)还有就是发现有一个数据项为
photoUrl,这是书籍封面的URL,同样可以抓取了保存下来,实现如下:1
2
3
4
5
6
7
8
9
10
11photoUrl = data['photoUrl']
if photoUrl != "":
print("save photo from" + photoUrl)
try:
r = requests.request("GET", photoUrl)
save_path = "./photo/" +str(data["code"]) + "." + photoUrl.split('.')[-1]
print(save_path)
with open(save_path, 'wb') as f:
f.write(r.content)
except:
print("save photo failed")
最终实现
整理以上代码,最终完整实现如下:
1 | import json |