CS61A——Lec-03-控制(含HW-01下)
主要内容
- 副作用
- 更多的函数特性
- 条件语句
- 布尔值
- 迭代
副作用
None值
None这个值在Python中表示没有,任何一个不显式返回值的函数都会返回None:
1 | def square_it(x): |
调用返回None的函数时,控制台不会有输出:
1 | square_it(3) |
如果将None当成一个数来使用的话会导致错误:
1 | sixteen = square_it(4) |
类型错误(TypeError):

副作用
副作用指的是调用函数时,除了返回值以外发生的其他的事。
如果常见的调用print()函数时会在控制台输出字符:
1 | print(-2) |
类似的副作用还有向文件写内容:
1 | f = open('songs.txt', 'w') |
副作用 vs. 返回值
代码段1:
1 | def square_num1(number): |
代码段2:
1 | def square_num2(number): |
其中square_num2()函数有副作用,因为它输出了值,但返回值为None;square_num1()返回的是一个数。
其中,仅返回值的函数称为纯函数(Pure function),有副作用的函数称为非纯函数(Non-pure function)。
嵌套print()语句
一个嵌套的print()语句:
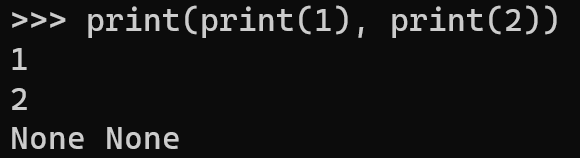
1 | print(print(1), print(2)) |
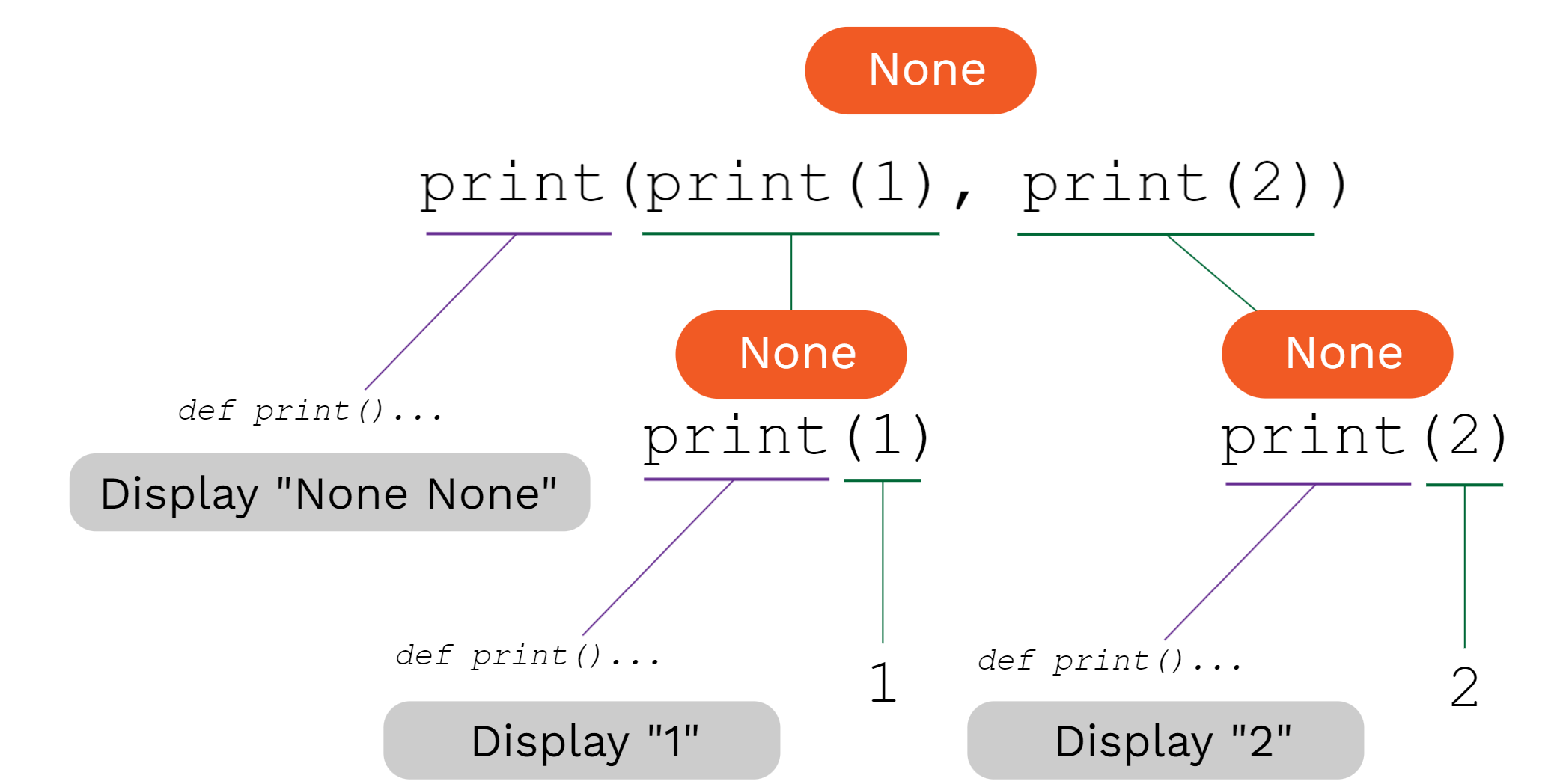
输出结果为:
更多的函数特性
默认参数
在函数签名中,参数可以指定一个默认值,如果没传值那就使用默认值。
1 | def calculate_dog_age(human_years, multiplier = 7): |
这两个调用结果是一样的:
1 | calculate_dog_age(3) |
默认的参数可以用两种方式覆盖:
1 | calculate_dog_age(3, 6) |
多个返回值
一个函数可以指定多个返回值,通过逗号,分隔:
1 | def divide_exact(n, d): |
任何调用该函数的代码都应该用,来解包:
1 | q, r = divide_exact(618, 10) |
Doctests
doctest可以检查函数的输入输出:
1 | def divide_exact(n, d): |
doctest会搜索类似交互式Python会话的片段,然后执行这些会话来验证是否一致。
doctest — Test interactive Python examples — Python 3.10.1 documentation
布尔表达式
布尔值
布尔值要么是True要么是False,很常用。
比如谷歌地图用布尔值确定是否在驾驶路线中避免高速路:
1 | avoid_highways = True |
比如推特用布尔值记住用户是否允许个性化广告:
1 | personalized_ads = False |
比较操作符
| 操作符 | 意义 | 为真的表达式 |
|---|---|---|
== |
等于 | 32 == 32 |
!= |
不等于 | 32 != 31 |
> |
大于 | 92 > 32 |
>= |
大于等于 | 92 >= 32,32 >= 32 |
< |
小于 | 20 < 32 |
<= |
小于等于 | 20 <= 32 |
注意:不要混用=和==。
逻辑操作符
| 操作符 | 意义 | 为真的表达式 |
|---|---|---|
and |
与,两边都为真结果才为真 | 4 > 0 and -2 < 0 |
or |
或,两边有一个为真结果就为真 | 4 > 0 or -2 > 0 |
not |
非,对真用就变成假,对假用就变成真 | not (5 == 0) |
复合布尔值
如果要在单个表达式中组合多个操作符,应该用括号来分组:
1 | may_have_mobility_issues = (age >= 0 and age < 2) or age > 90 |
函数中的布尔表达式
函数可以用布尔值作为返回值:
1 | def passed_class(grade): |
1 | def should_wear_jacket(is_rainy, is_windy): |
语句
语句
解释器执行一条语句来执行一个动作,已经遇到的有:
赋值语句
1
2name = 'sosuke'
greeting = 'ahoy, ' + name函数定义语句
1
2def greet(name):
return 'ahoy, ' + name返回语句
1
return 'ahoy, ' + name
复合语句
一个复合语句包含一组其他语句:
1 | <header>: |
第一行的头类型,每个复合语句的头控制后面跟着的语句。
整个复合语句叫做一个clause,后面跟着的语句序列叫做suite,不知道怎么翻译更贴切。
Suites的执行
Suite就是上一部分的一个语句序列,执行规则:
- 执行第一条语句;
- 除非另有指示,不然执行剩余的语句;
条件语句
条件语句
条件语句基于确定的条件是否成立来决定是否执行suite:
1 | if <condition>: |
一个例子:
1 | clothing = "shirt" |
复合条件
条件语句可以包含任意数量的elif语句来检查其他条件:
1 | if <condition>: |
一个例子:
1 | clothing = "shirt" |
else语句
条件语句可以包含一个else来指定在前面的条件都不满足时执行的代码。
1 | if <condition>: |
1 | if temperature < 0: |
条件语句总结
1 | if num < 0: |
- 总是以
if子句开头; - 0个或多个
elif子句; - 0个过一个
else子句,总是在最后一个;
条件语句的执行
每个子句按顺序来执行:
- 求头表达式的值;
- 如果结果是真,执行这个子句下的suite并跳过剩下的子句;
- 否则,继续执行下一条子句;
函数中的条件语句
一种常见的情况就是条件语句基于函数的参数:
1 | def get_number_sign(num): |
条件语句中的返回
一个条件语句的分支可以以return语句结束,这样会退出整个函数:
1 | def get_number_sign(num): |
while循环
while循环
while循环的语法:
1 | while <condition>: |
只要条件的结果为真,那后面的语句就会执行。
1 | multiplier = 1 |
循环可以缩短代码,并且很容易拓展为更多或更少次迭代。
使用一个计数器变量
可以使用一个计数器变量来追踪迭代的次数:
1 | total = 0 |
计数器变量也可以参与循环中的计算:
1 | total = 0 |
注意无限循环
比如:
1 | counter = 1 |
会一直循环下去,因为条件始终满足,应该在循环中修改计数器变量:
1 | counter += 1 |
还有这种情况:
1 | counter = 6 |
同样条件始终满足,应该修改初始化值和循环条件。
循环的执行
- 对头布尔表达式进行求值;
- 如果结果为真,则执行语句的suite,然后回到步骤1;
函数中的循环
函数中的循环通常会使用参数来确定其重复的起始值:
1 | def sum_up_squares(start, end): |
break语句
想要提前跳出循环,可以使用break语句:
1 | counter = 100 |
while True:的循环
你要是很勇的话,可以这么写循环:
1 | counter = 100 |
不过得确保不是无限循环。
一个例子:质因子
质数是大于1且仅能整除1和它本身的整数。
1 | def is_prime(n): |
第一个函数不用修改,利用的是质数的定义:
- 大于1;
- 最小的因子是他本身;
第二个函数就是要求他的最小因子,思路必须是这样:
- 计数器变量从2开始循环,最大到
n,计算n是否整除计数器变量; - 如果可以整除,返回计数器变量的值;
- 否则计数器变量加一,进入下一循环;
代码如下:
1 | def smallest_factor(n): |
第三个函数是要输出所有因子,思路如下:
- 用
smallest_factor()函数找到n的最小因子,输出这个因子; n /= factor,返回第一步;
可以用递归的思想,但其实效率不高,也可以就单纯循环,单纯用循环代码如下:
1 | def print_factors(n): |
其实上面的代码可以改函数参数的话是可以进一步优化的:
- 既然
counter已经是n的最小质因子,那么n // counter的最小质因子肯定不小于counter,也就是说继续计算最小质因子的时候可以从上一轮的最小质因子开始遍历; - 在循环查找最小质因子时,
counter超过n的平方根后就可以不用继续了,直接返回n即可;
那么稍微优化一下:
1 | from math import sqrt |
虽然效率还是很低,但至少比之前快很多!
Homework
Largest Factor
写一个函数,输入是大于1的整数n,要返回n的小于n的最大因子:
1 | def largest_factor(n): |
直接从n-1开始往1循环就行:
1 | def largest_factor(n): |
If Function Refactor
有两个函数有相似的结构,都用if语句防止x为0时的除零错误(ZeroDivisionError):
1 | def invert(x, limit): |
重构的意思是重写一个程序,保持相同的功能但是设计上有变化。
这里给了个重构,定义了一个新的函数limited来包含他们的共同结构,这样每个函数就只有一行了:
1 | def limited(x, z, limit): |
但是这个重构有问题,执行invert_short(0, 100)会导致ZeroDivisionError,为什么?
问题1:为什么会报错?
问题2:修改代码。
回答1:因为在invert_short()里面调用的是limited()函数,首先是需要把输入参数表达式计算出来传递给limited()的参数,因此这里就已经在尝试计算1/x了,所以会报错,limited()里面的判断没有起到作用。
回答2:把除法放到limited()函数里面执行即可:
1 | def limited(x, z, limit): |
Hailstone
拿普利策奖的Douglas Hofstadter在Pulitzer-prize-winning book里面提出了一个数学谜题:
- 选一个正整数
n作为开始; - 如果
n是偶数,那就除以2; - 如果
n是奇数,那就乘以3再加1; - 重复过程,直到
n为1.
这个数会增增减减但是最后还是会变成1,试了很多数字都没问题,也没法证明这个序列会终止。冰雹在降落的时候也会上上下下,因此这种序列就叫冰雹序列。
现在就是要写一个函数,输出过程中的数,并返回这个序列的步数:
1 | def hailstone(n): |
直接写个循环就行了,循环里面判断奇偶,直到数变为1:
1 | def hailstone(n): |
题目还让试试输入为27的情况,测试了序列长度为112,最终还是回到了1。
Quine(附加题,Just for fun,浪费了我很久的时间)
写一个程序打印它自己,只能使用这些Python特性:
- 数字;
- 赋值语句;
- 可以使用单引号或双引号表示的字符串文字;
- 加减乘除运算符;
- 内置的
print函数; - 内置的
eval函数,这个函数会把字符串作为Python表达式求值; - 内置的
repr函数,会返回求值结果为他的参数的表达式;
可以通过加号拼接两个字符串,通过乘号重复字符串,分号可以用于在一行内分隔多条语句,比如:
1 | c='c';print('a');print('b' + c * 2) |
打印自己的程序叫Quine,把解决方案方案多行字符串quine里面:
1 | "*** YOUR CODE HERE ***" |
提示是利用单双引号的关系,并把repr函数用在字符串上。
这题我不会,通过查资料和测试才得到正确结果:
1 | quine= '''var = "print('var = ', repr(var) + ';', 'eval(var)')"; eval(var)\n''' |
三引号里面才是quine的本体,它执行的结果和代码本身的文本是一致的:
1 | var = "print('var = ', repr(var) + ';', 'eval(var)')"; eval(var) |
从结果来看肯定没问题,执行的话就是一句赋值加上一句eval,eval语句执行了字符串里面的内容,即执行了:
1 | print('var = ', repr(var) + ';', 'eval(var)') |
但是具体是怎么得到的,我能力有限,还是难以理解。